Data Vault Acceleration
Tackling the Architect’s Dilemma on Databricks
July 16, 2025
You’re tasked with building scalable data models on Databricks, but schema drift, unclear ownership, and complex pipeline logic are turning every iteration into a bottleneck. Sound familiar? Managing data pipelines in a modern data warehouse environment demands a balance between agility and control.
Without a clear strategy, maintaining consistency and adapting to change can slow down delivery and increase technical debt.
Addressing these challenges calls for an approach that handles complexity while speeding up development cycles. Metadata-driven automation with BimlFlex for Data Vault modeling offers a promising way to manage multiple source systems, evolving schemas, and incremental development, all while maintaining a clean, auditable architecture. This methodology represents both comprehensive Data Vault automation and the broader benefits of streamlining Databricks solutions with BimlFlex data automation across the entire data platform.
This article explains how data vault acceleration, driven by metadata and automation, can help architects on Databricks overcome these issues. We’ll explore how to set up and optimize your data vault model logically and physically, manage satellite splitting, combine or separate links, and publish your design incrementally to keep control without slowing down delivery.
Understanding the Challenges of Data Vault Modeling on Databricks
Data Vault modeling is a popular approach to building scalable, flexible, and auditable data warehouses. However, architects face several common problems when implementing it on platforms like Databricks:
- Schema Drift: Source systems evolve continuously, causing changes in schemas that can break pipelines or cause inconsistencies.
- Complex Pipeline Logic: Managing multiple sources with different structures requires complex transformation logic that can become hard to maintain.
- Unclear Ownership: Without clear mapping between source data and target models, teams struggle to know who owns what data element and how changes should propagate.
- Slow Iterations: Building and deploying changes to the data vault can be time-consuming, especially when done manually or without automation.
To overcome these, a metadata-driven, automated approach to building and accelerating data vault models can be a game changer. It helps maintain consistency, handle change gracefully, and deliver value faster.
Setting the Foundation: Key Configuration for Data Vault Acceleration
Before starting data vault modeling, it’s important to configure your environment correctly. One critical setting is the infer link hub option. This controls how links and hubs are inferred during model creation. Currently, it’s recommended to set this to no to avoid partial or inconsistent implementations, especially if you are using ELT patterns. This setting is fully supported in SSIS patterns and will be completely implemented in upcoming releases.
Another important area is the hashing configuration. Hashing is fundamental in data vault modeling to detect changes and maintain data integrity. Supported hash algorithms include MD5, SHA-1, SHA-256, and SHA-512. SHA-1 is a common default choice, balancing security and performance.
Additionally, you can choose between binary or text hashing. Binary hashing is preferred for efficiency. Make sure to enable SQL-compatible row hashing to keep your hashes consistent with database functions like Snowflake's SHA1. This compatibility is vital for reliable change detection across platforms.
There is also an option to accelerate link satellites or effective satellites. This can be turned on later if you want to optimize link satellite handling, but leaving it off by default keeps the configuration straightforward.
These technical considerations are fundamental to building a reliable Data Vault project that can scale and maintain data integrity over time.
Designing Your Target Data Vault Model
The heart of data vault acceleration lies in designing the target model logically before physical implementation.
The process involves three key steps:
- Design the target model:Define hubs, links, and satellites based on your business concepts.
- Map sources to the target: Use metadata heuristics to relate source tables and columns to your target objects.
- Publish incrementally: Move from logical models to physical tables in stages, allowing controlled delivery.
Automation tools can analyze your source metadata and forward engineer a data vault model. For example, a source table like SalesOrderHeader can automatically generate a hub and its related links based on existing relationships.
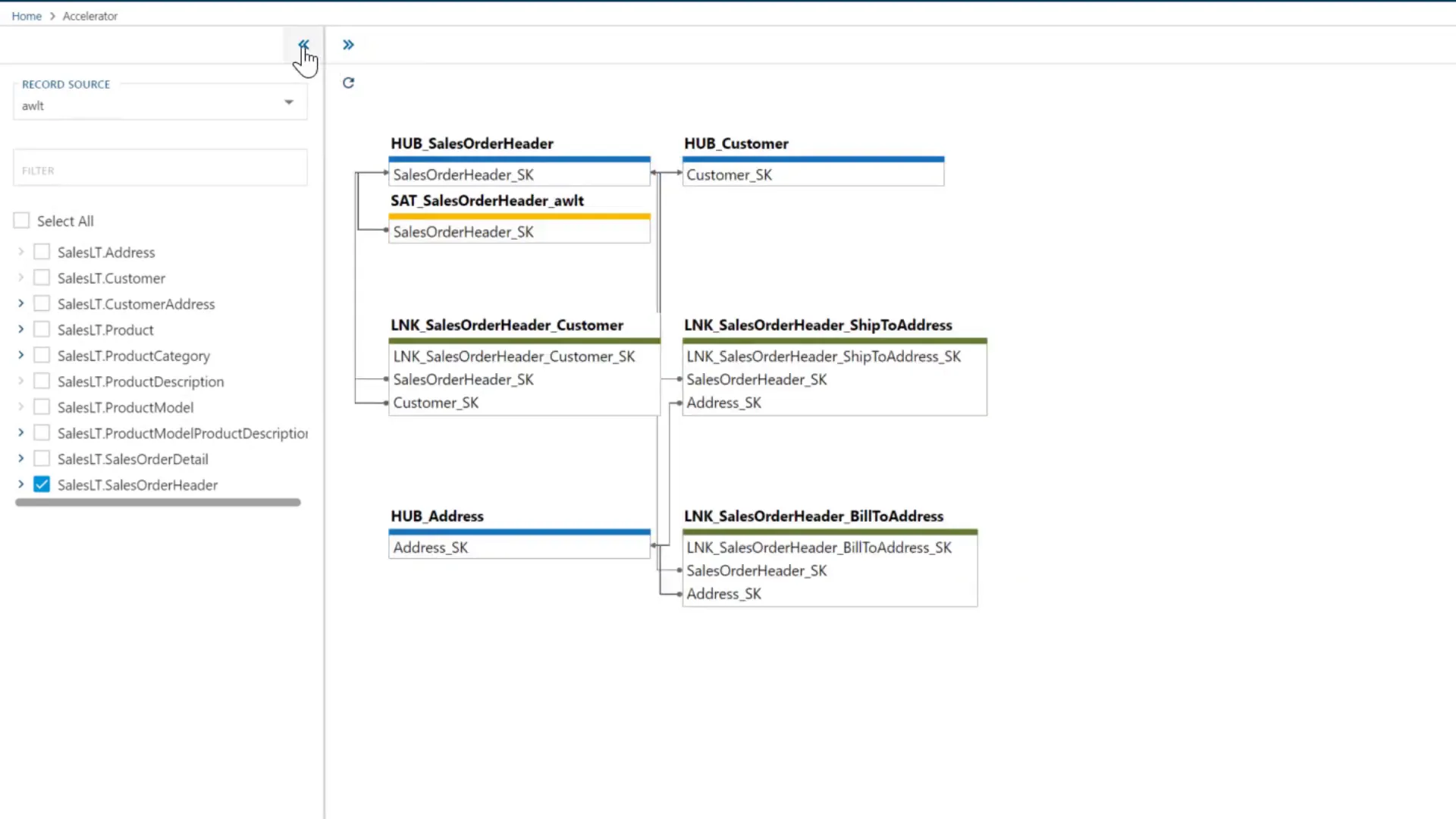
One practical feature is the ability to override default naming conventions. If your business prefers calling SalesOrderHeader simply SalesOrder, you can rename the hub easily in the source table’s model override name. This helps keep the model aligned with business terminology and improves clarity for stakeholders.
Combining and Splitting Links for Business Logic
Links in a data vault represent natural business relationships or units of work.
Deciding whether to combine multiple links into a single logical link or keep them separate is an important modeling choice.
With a metadata-driven interface, combining links is as simple as dragging one link onto another and renaming the combined entity to represent the unit of work. This flexibility lets you refine your model iteratively as you better understand business processes.
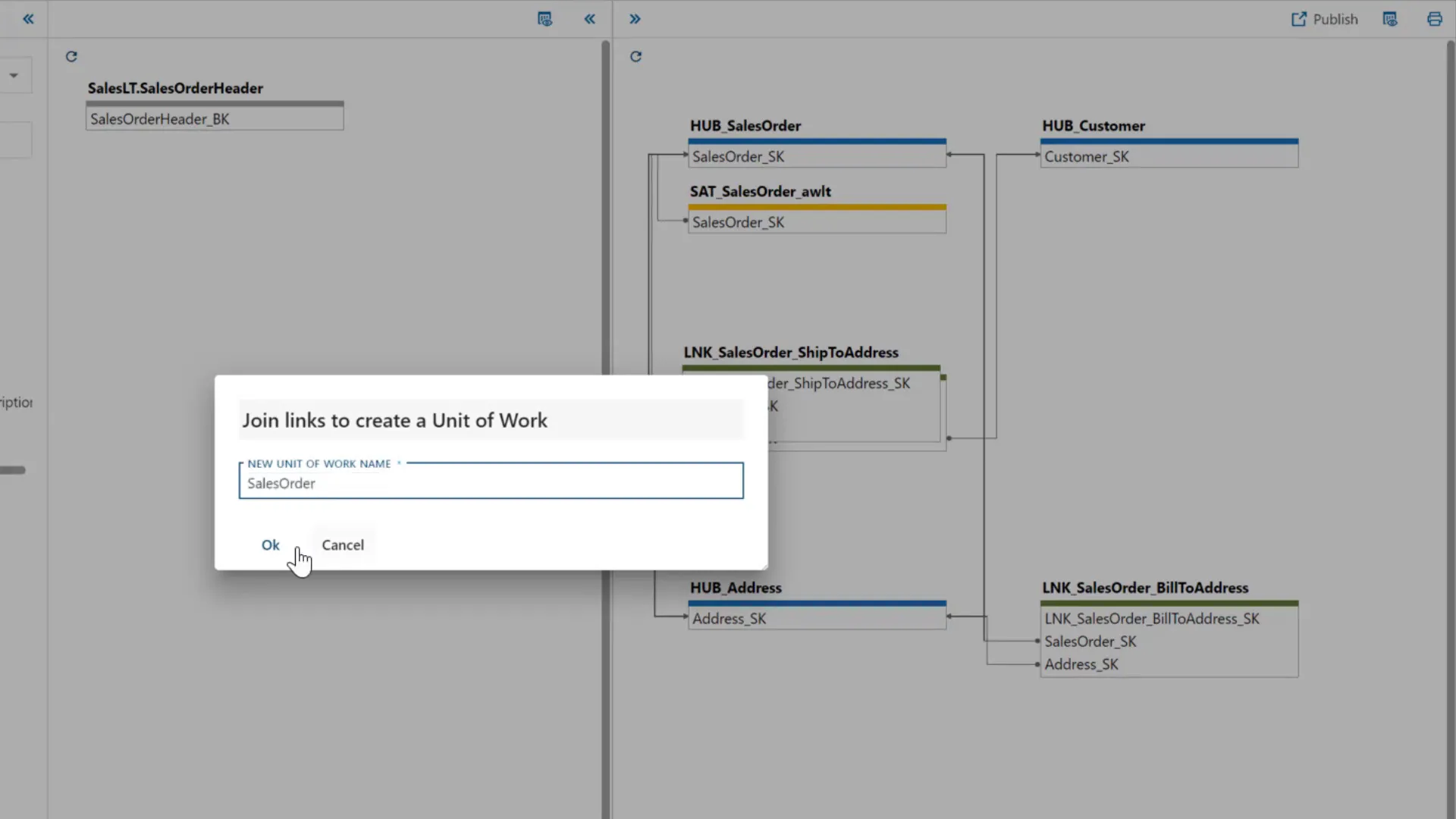
If a link like PullToAddress is found to be unrelated to the main unit of work, you can easily split it back out into its own satellite or link. This agility helps maintain accuracy in the data vault and prevents mixing unrelated entities.
Satellite Splitting and Column Exclusion for Better Data Management
Satellites hold descriptive attributes related to hubs and links. Managing satellites effectively is crucial for performance and clarity.
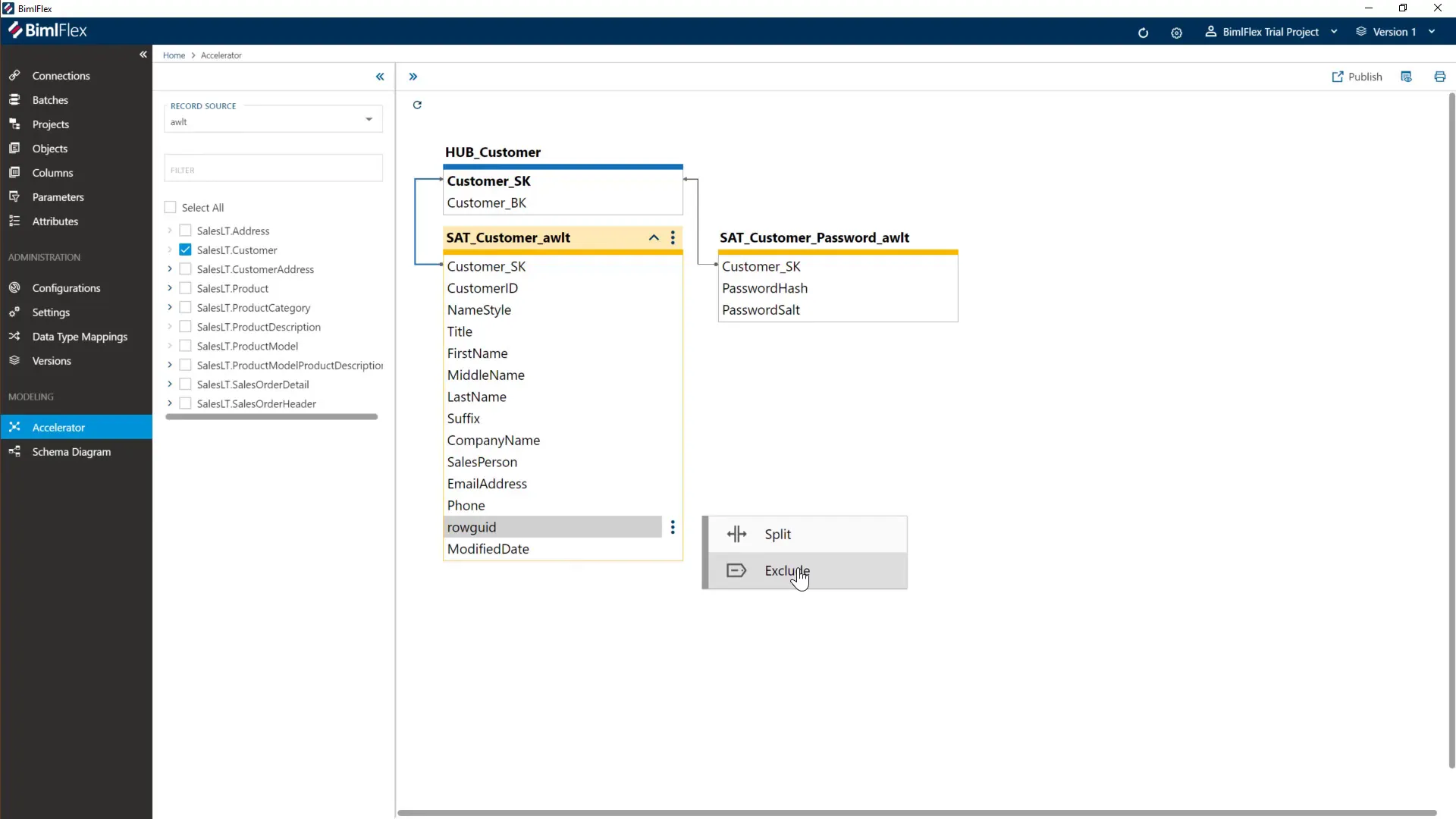
When analyzing your source columns, you might find some attributes that change frequently and should be isolated in their own satellites. For instance, columns related to passwords or security tokens can be split out to minimize unnecessary data reprocessing.
Select the columns to split, create a new satellite, and assign the columns. This modular approach keeps your data vault clean and efficient.
Additionally, some columns may not be needed in the data vault but still need to be extracted to staging. You can exclude these columns from the data vault model without affecting the extraction process. This selective inclusion reduces clutter and improves model focus.
Creating Common Satellites Across Multiple Sources
Integrating multiple source systems often reveals attributes that are common across all systems, such as personal names or contact details. These can be grouped into a shared satellite to avoid duplication and simplify integration.
By removing the record source from these satellites, you create integrated satellites that consolidate data from all sources. This approach supports a consistent view of core entities like customers.
Another useful concept is the bag of keys, which collects all source keys in a single satellite. This makes key management easier and supports linking across heterogeneous systems.
Incremental Publishing: From Logical Model to Physical Data Vault
The ability to build your data vault incrementally is a major advantage. Initially, the model exists only logically, tracking metadata and heuristics about how columns map to satellites and keys. At this stage, no physical tables are created, allowing flexible design and review.
Once satisfied with your logical model, you can publish it to create physical tables. This step can be done incrementally, focusing on high-priority business concepts first and adding more objects over time. Incremental publishing reduces risk and accelerates delivery.
For example, after modeling several source tables, you may choose to publish only the core hubs and links related to sales orders, leaving others for later.
After publishing, you can inspect the created physical objects such as hubs, links, and satellites. The relationships and keys are fully implemented, ready for data loading and analysis.
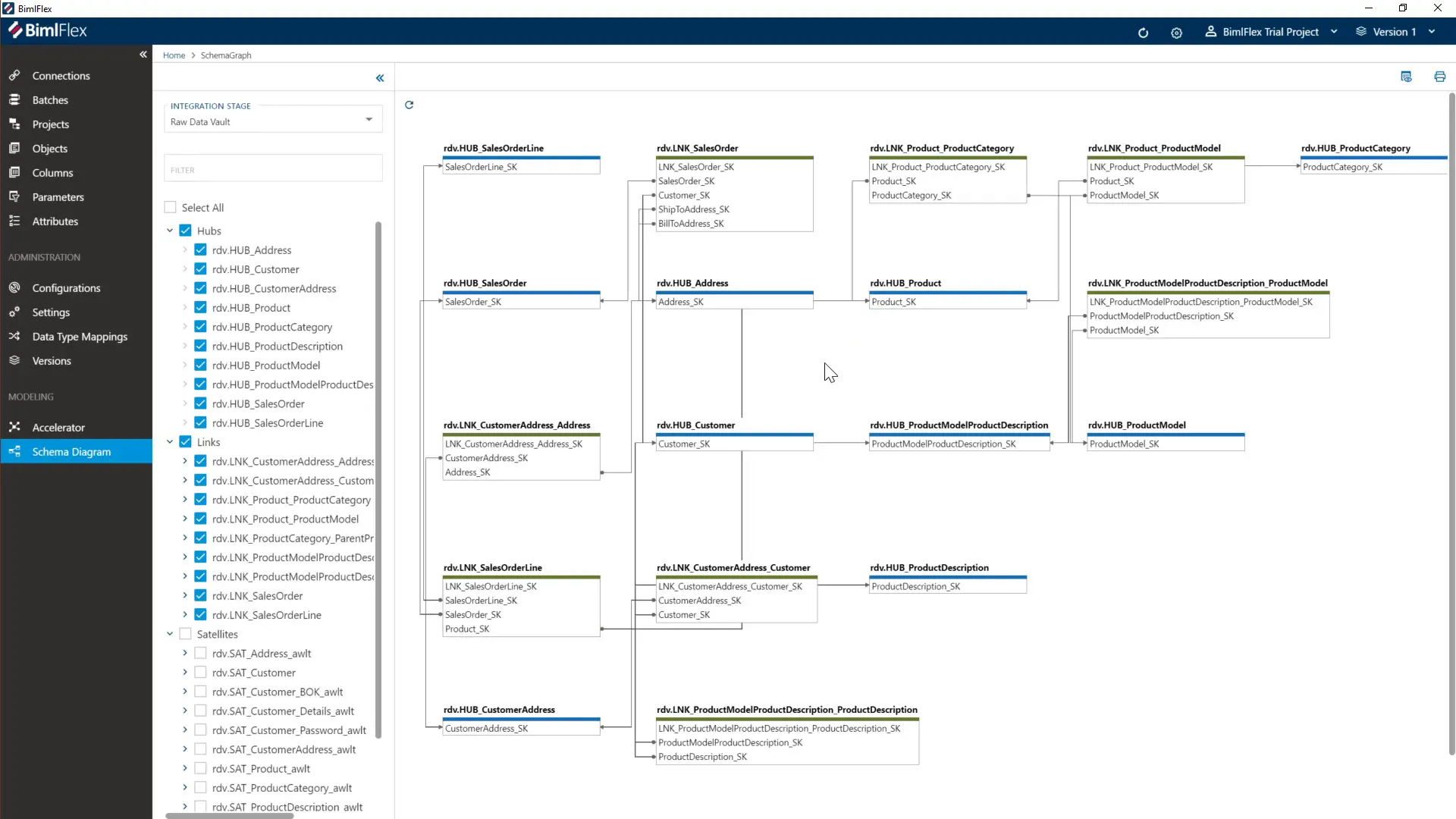
Schema Diagrams and Model Review
Schema diagrams help visualize both source systems and the data vault backbone. You can generate diagrams showing hubs, links, and satellites, making it easier to review with your team and ensure alignment with business requirements.
Building and maintaining data vault models on Databricks presents strategic and technical challenges. Schema drift, unclear ownership, and complex transformation logic can slow down delivery and increase risk.
Using BimlFlex's metadata-driven automation to accelerate data vault development offers a practical solution. This approach helps architects manage complexity, adapt to change, and deliver faster without sacrificing control or consistency.
Ready to tame complexity and speed up delivery?
Schedule a demo to see how BimlFlex helps Databricks architects automate Data Vault modeling, adapt to change faster, and build audit-ready pipelines without the drag of manual. work.
FAQ
What is data vault acceleration?
Data vault acceleration is the process of using metadata-driven automation to quickly generate and manage data vault models. It helps convert source metadata into hubs, links, and satellites with minimal manual effort.
Why is incremental publishing important in data vault modeling?
Incremental publishing lets you build your data vault step-by-step, focusing on priority areas first. This reduces risk, allows early feedback, and speeds up delivery without waiting for the entire model to be complete.
How do I decide when to split satellites?
Satellites should be split when they contain attributes that change at different rates or have distinct business meanings. For example, security-related columns can be isolated to reduce unnecessary data reloads.
What is the benefit of removing the record source from satellites?
Removing the record source creates integrated satellites that consolidate attributes common across multiple source systems. This facilitates a unified view of entities like customers or products.
Can I customize naming conventions for hubs and links?
Yes. You can override default names to match business terminology, improving clarity and communication with stakeholders.