BimlFlex Automation End to End
Part 1: Foundation and Frameworks
May 1, 2025
In today’s fast-evolving data landscape, organizations face constant pressure to deliver trusted data faster, adapt to schema drift, and reduce pipeline sprawl. Doing this at scale, while meeting governance and audit requirements, requires more than just speed. It demands structure, automation, and flexibility.
This two-part walkthrough explores how a metadata-driven framework like BimlFlex helps overcome those challenges. In Part 1, we’ll focus on setting up the metadata foundation, modeling the Data Vault layer, and enabling automated deployments. Part 2 (coming next) will cover performance tuning, data mart delivery, and build error resolution.
Table of Contents – Part 1
- Simplifying Metadata Management and Project Setup
- Incremental and Automated Data Vault Modeling
- Metadata-Driven Build and Deployment Automation
- Parameterizing Source Queries for Incremental Loads
- Why It Matters: Delivering Reliable, Scalable DataWarehouses Faster
1. Simplifying Metadata Management and Project Setup
A core difficulty in traditional data warehouse projects is the manual, error-prone setup of metadata and connections between source systems, staging, and target layers. BimlFlex tackles this by providing a structured way to manage metadata through a central project and customer model.
Initially, users create a new customer connection in the BimlFlex app, selecting the appropriate database server and authentication method. This step establishes the foundational metadata snapshot that the entire project builds upon. Loading sample metadata, such as the Microsoft SQL Server AdventureWorksLT database, provides a concrete starting point.
Simultaneously, the BimlStudio project is created to house the code artifacts that generate the physical data warehouse objects. The BimlStudio project connects directly to the metadata database, ensuring synchronization between logical metadata and physical implementation.
This approach eliminates the common disconnect between metadata management and code development by tightly coupling them. It also lays the groundwork for incremental and repeatable builds, reducing rework and improving traceability.
1.1 Benefits of Metadata-Driven Project Initialization
- Consistency: Centralized metadata ensures consistent definitions across environments.
- Reusability: Sample metadata accelerates onboarding and provides templates for common patterns.
- Flexibility: Easily switch between authentication methods and database targets without rework.
- Traceability: Versioned customer projects enable audit trails and rollback capabilities.
2. Incremental and Automated Data Vault Modeling
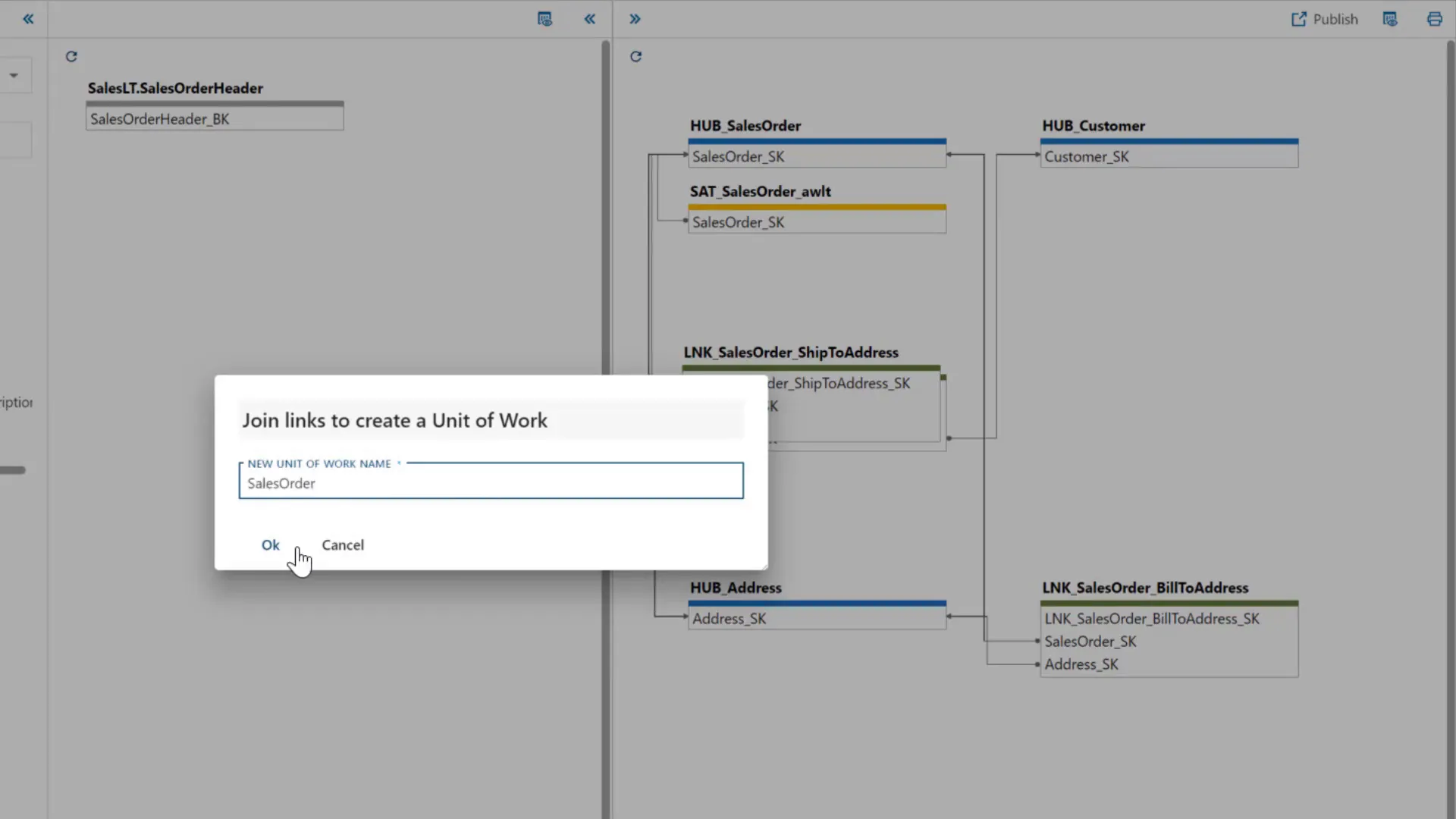
Modeling a Data Vault architecture manually can be cumbersome due to the need to analyze source systems, design hubs, links, and satellites, and maintain consistent naming conventions. BimlFlex alleviates this challenge by applying heuristics to forward engineer a Data Vault model directly from the imported metadata.
Users can visually inspect and adjust the automatically generated hubs and links. For example, combining multiple links into a single unit of work or splitting satellites based on attribute volatility is intuitive and interactive. This incremental approach allows teams to start with core business concepts and expand the model over time.
Furthermore, data type mappings enable handling complex source data types, such as converting XML columns into manageable string formats, improving compatibility and simplifying ETL logic.
2.1 Benefits of Incremental Data Vault Modeling
- Efficiency: Automates repetitive modeling tasks, reducing manual effort.
- Governance: Centralized metadata changes propagate consistently through the model.
- Flexibility: Supports evolving business rules by allowing easy link and satellite adjustments.
- Scalability: Incremental publishing enables managing large source systems in manageable chunks.
3. Metadata-Driven Build and Deployment Automation
One of the most time-consuming aspects of data warehouse development is the creation and maintenance of physical tables, stored procedures, and ETL packages. BimlFlex automates this by generating build scripts, stored procedures, and SSIS packages based on the logical metadata model.
Users can generate table creation scripts, stored procedures for loading Data Vault layers, and default insert scripts that establish ghost or dummy records to maintain referential integrity. The generated SSIS packages orchestrate loading processes with configurable parallelism via batch threads.
This automation not only accelerates development but also reduces human error and simplifies continuous integration and deployment (CI/CD) pipelines.
3.1 Benefits of Automated Build and Deployment
- Speed: Rapid generation of physical objects and ETL packages.
- Reliability: Consistent build artifacts reduce deployment errors.
- Scalability: Configurable threading optimizes load performance.
- Maintainability: Centralized metadata updates trigger downstream changes automatically.
4. Parameterizing Source Queries for Incremental Loads
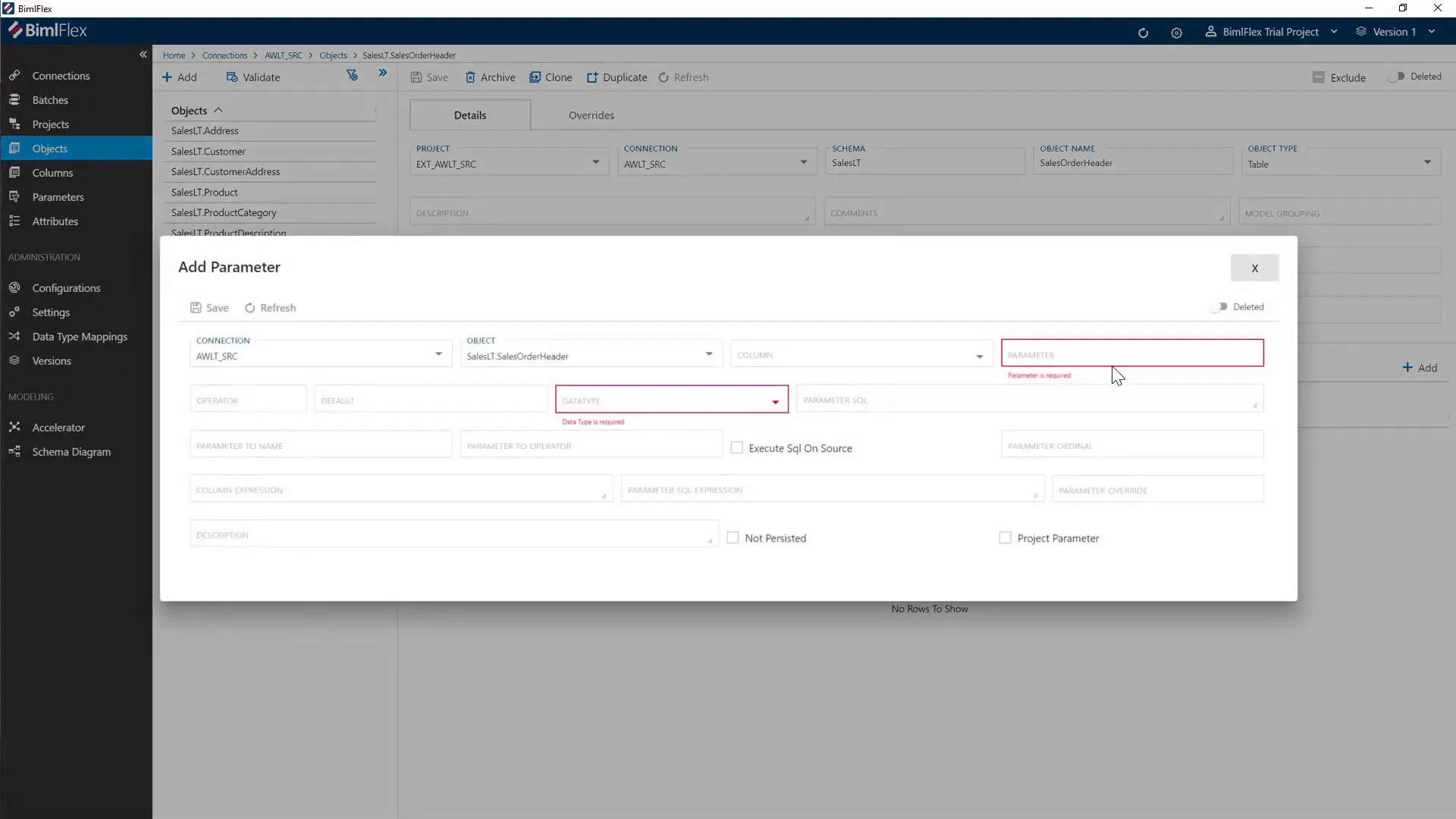
Efficient data loading requires incremental extraction based on high watermark columns like modification dates. BimlFlex supports query parameterization, enabling packages to fetch only changed data since the last load.
Parameters can be added to source objects specifying the column, operator, default values, and SQL to retrieve the next load date. Although parameters are stored as strings due to SSIS limitations, this design offers flexibility in handling different data types.
For bulk parameter management, the integration with Excel allows users to retrieve, modify, and push parameter metadata back to the system efficiently, streamlining configuration across many tables.
4.1 Benefits of Parameterized Queries
- Performance: Reduces data volume transferred by extracting only changed rows.
- Maintainability: Centralized parameter management reduces configuration drift.
- Scalability: Supports complex extraction logic tailored per source object.
5. Why It Matters: Laying the Groundwork for Scalable Automation
The early stages of any data warehouse project often determine its long-term success.
By investing in a strong metadata foundation and automating core modeling and deployment tasks, teams can avoid the pitfalls of manual setup, inconsistent naming, and rigid design choices.
BimlFlex simplifies this critical phase, allowing teams to:
- Establish consistency across projects and environments through centralized metadata.
- Accelerate onboarding with reusable templates and guided project setup.
- Enable adaptability by designing models that evolve incrementally with business needs.
- Reduce rework by linking metadata directly to build artifacts and automation logic.
This upfront investment in structure and automation pays off throughout the pipeline, setting the stage for high-quality, low-maintenance data delivery down the line.
In Part 2, we’ll focus on optimizing performance, delivering business-ready data marts, and managing configuration and deployment at scale.
Explore how metadata-driven modeling with BimlFlex sets the foundation for consistent, auditable, and scalable data pipelines. Then, stay tuned for Part 2 where we tackle optimization, data mart delivery, and build resilience at scale.
Start strong, scale smarter.
Schedule a demo today and start automating tomorrow.