Dev Diary - Using Mapping Data Flow Parameters to dynamically use BimlFlex metadata
August 22, 2021
When using Mapping Data Flows for Azure Data Factory with inline datasets, the schema can be evaluated at runtime. This also paves the way to use of one of the key features this approach enables, which is support for schema drift.
Schema drift allows to evaluate or infer changes made to the schema (data structure) that is read from or written to. Without going into too much detail on this for now, the key message is that the schema is not required to be known in advance and can even change over time.
This needs to be considered for the new Data Flow Mapping patterns for BimlFlex. The Data Flow Mappings may read from multiple sources of different technology and write to an equal variety of targets (sinks), and some have stronger support for defining the schema than others.
Moreover, various components that may be used in the Data Flow Mapping require a known or defined column to function. This is to say that a column needs to be available to use in many transformations; in many cases this is mandatory.
The approach we are pioneering with BimlFlex is to make sure the generated patterns / Data Flow Mappings are made sufficiently dynamic by design by using Data Flow Mapping Parameters, so that we don't need to strictly define the schema upfront. The BimlFlex generated output for Data Flow Mappings intends to strike a balance between creating fully dynamic patterns that receive their metadata from BimlFlex, and allowing injecting custom logic using Extension Points.
Using Data Flow Mapping Parameters goes a long way in making this possible.
Using parameters, various essential columns can be predefined both in terms of name as well as value. This information can be used in the Data Flow Mapping using the dynamic content features provided.
Consider the following screenshot of one of the generated output that loads new data form file into a Delta Lake staging area:
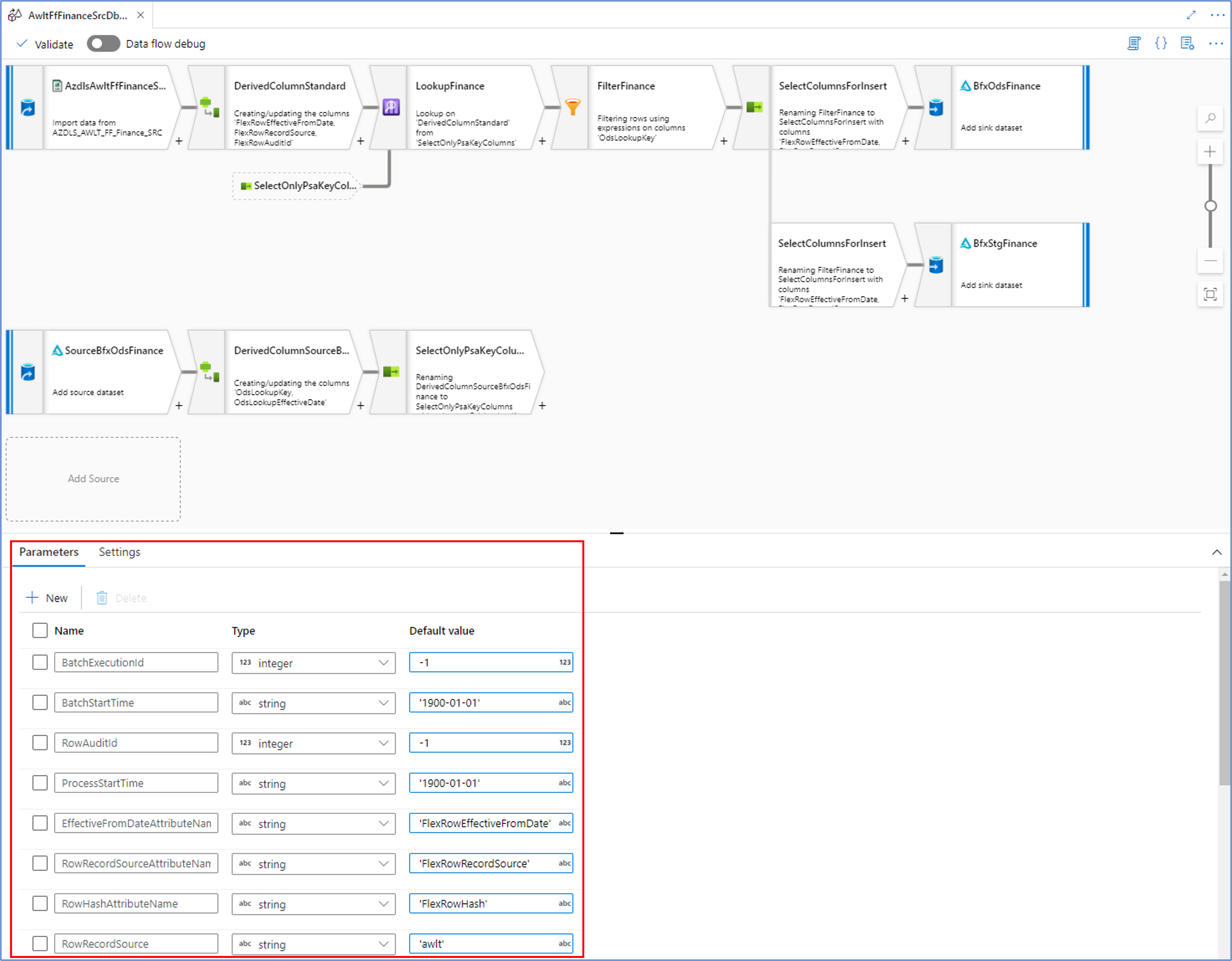
In our WIP approach, BimlFlex generates the essential metadata as parameters which are visible by clicking anywhere on the Data Flow Mapping canvas outside of the visible components.
As an example, the ‘RowRecordSource’ parameter contains the name of the Record Source value from the BimlFlex metadata. This can be used directly in transformation such as in the Derived Column transformation below:
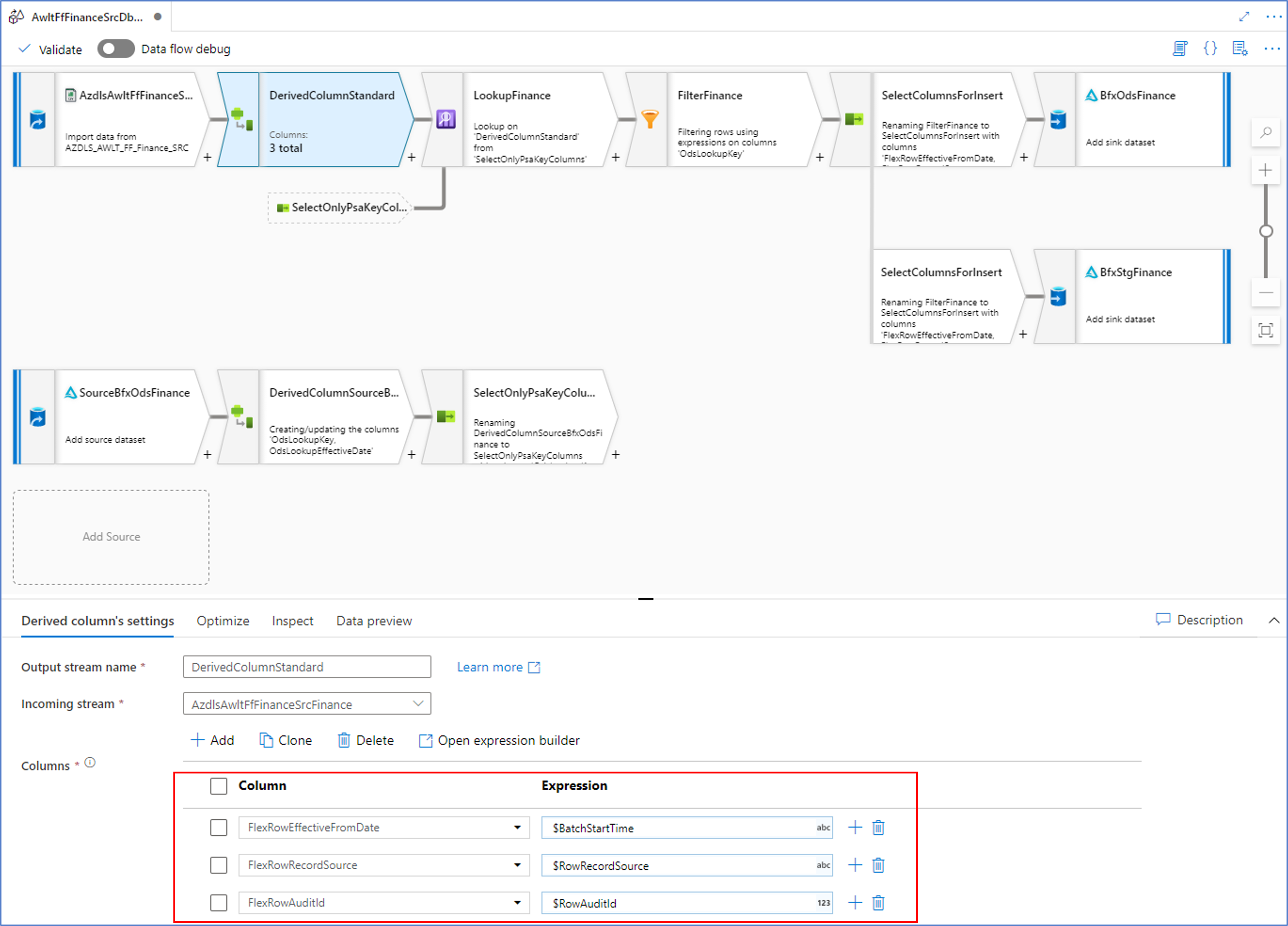
This means that we can use the names of the necessary columns as placeholders in subsequent transformations and their value will be evaluated at runtime. This can also be used to dynamically set column names, if required.
In the next posts, we’ll look at the Biml syntax behind this approach for the various transformations / components used.