How to Build and Deploy for Azure Data Factory
June 23, 2025
Moving and managing data across modern cloud environments remains a challenge for many organizations. Data teams often struggle with the complexity of building reliable data pipelines that efficiently transfer data from source systems into the cloud, while keeping everything manageable and scalable. These challenges reflect broader issues outlined in the top five challenges of data lakes, where complexity and scale create similar obstacles to effective data management.
One common hurdle is automating the creation and deployment of data factory pipelines that orchestrate data movement and transformation. Without automation, teams spend too much time stitching together connections, configuring pipelines, and deploying code. This reduces agility and increases the risk of mistakes.
Addressing these challenges requires a streamlined approach to building and deploying pipelines that reduces manual effort and integrates well with cloud services.
When building and deploying pipelines in Azure Data Factory, even the smallest inefficiencies can snowball into major delays.
That’s where automation comes in.
In this article, we’ll explore how BimlFlex streamlines the entire process, from environment setup and metadata import to pipeline generation and deployment, so your data workflows stay fast, consistent, and error-free.
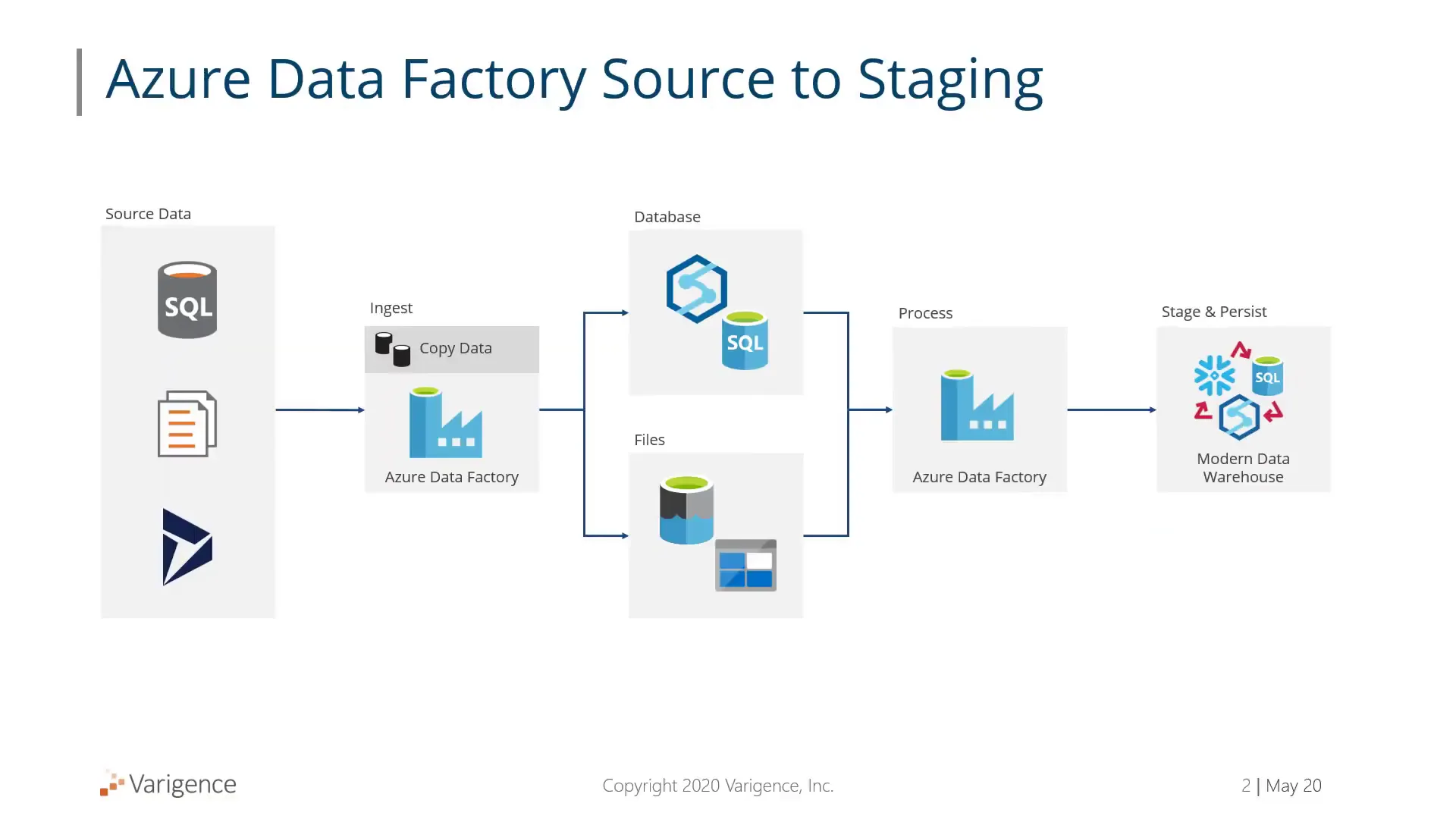
Setting Up Your Azure Data Factory Environment
Before building any pipelines, the environment needs to be configured properly. This setup ensures the automation process has all the necessary details to connect and deploy assets correctly.
Start by defining the key parameters for your Azure Data Factory environment:
- Data Factory Name: This is the name of your Azure Data Factory instance where pipelines will be deployed.
- Subscription ID: The Azure subscription ID under which your data factory and related resources reside.
- Resource Group: The Azure resource group that contains your data factory and other linked services.
These settings can be configured within your metadata or environment settings. While you don’t have to include subscription ID and resource group in the metadata, it is recommended if you plan to build and deploy pipelines frequently, especially in development environments.
For example, you might have an Azure Data Factory named BimlFlex, and you would enter that name along with your subscription ID and resource group in the respective configuration fields.
This setup primes the system to deploy pipelines and associated resources to the correct Azure environment.
Importing Metadata from Your Source Database
Once the environment is ready, the next step is to bring in metadata from your source system. Metadata defines the tables, columns, and relationships which are crucial for generating accurate data pipelines.
In this example, metadata is imported from the Adventure Works LT sample database. The process is straightforward:
- Connect to the source database using the configured connection.
- Select the tables you want to include in your data pipelines.
- Import the metadata, which will load table definitions, columns, and schema relationships into your project.
This import gathers enough metadata for BimlFlex to understand the data structure and dependencies. With this information, it can automatically determine the order in which tables should be extracted and loaded to maintain referential integrity.
After import, you can view and modify metadata as needed, such as adding custom SQL statements or adjusting table properties. However, for landing raw data, the default metadata import usually suffices.
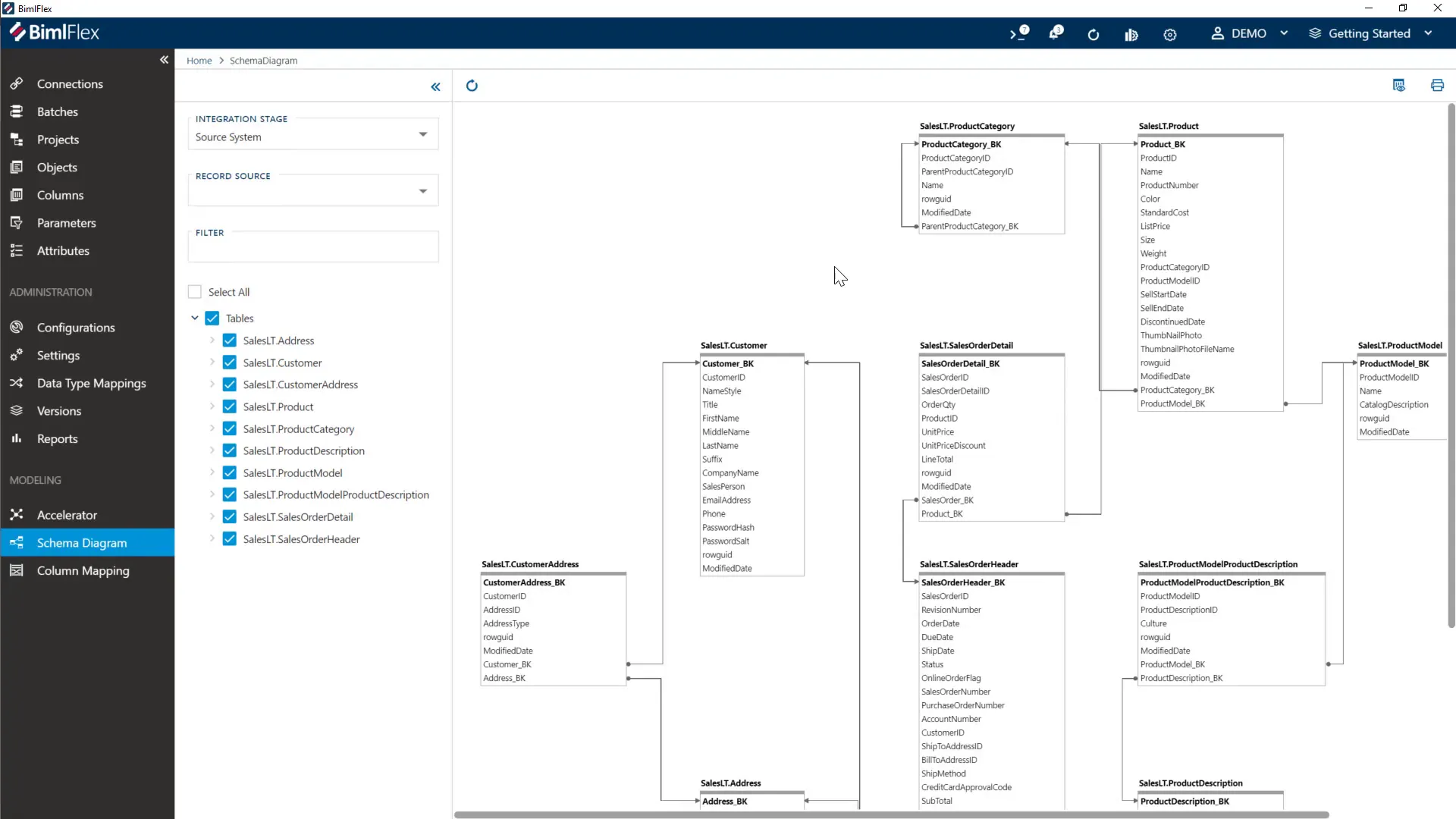
Visualizing the Schema
Having a visual overview of the schema helps understand the relationships and flow of data.
BimlFlex provides a schema view where you can select tables and see their connections. This visual representation confirms the metadata import and assists in planning pipeline execution order.
Building Pipeline Assets Automatically
With metadata and environment settings in place, you can now build the actual pipeline code. This step generates all the necessary Azure Data Factory assets based on the metadata.
When you hit the build button, BimlFlex creates a comprehensive set of files and scripts, including:
- ARM templates for Azure resource deployment
- JSON files representing Data Factory pipelines, datasets, and linked services
- PowerShell scripts for automated deployment
- SQL Server Data Tools projects for deploying database objects and stored procedures
This output is organized in folders such as DataFactories for ARM templates and JSON files, Deploy for build and deployment scripts, and others for SQL deployment projects. You can use these assets directly to deploy pipelines or integrate them into continuous integration (CI) workflows.
The build process respects Azure Data Factory limits, such as the 40-activity limit per pipeline. It automatically breaks up copy activities into batches and sub-batches to comply with these constraints, ensuring pipelines run smoothly.
Deploying Pipelines to Azure Data Factory
Deployment is done using PowerShell scripts that execute ARM templates with the proper parameters.
This automates provisioning of linked services, datasets, pipelines, and other resources in your Azure Data Factory instance.
Running the deployment script connects to Azure, submits the ARM template, and provisions all assets. Once complete, you can verify the deployment inside the Azure portal.
In the Azure Data Factory portal, you will see your pipelines organized into batches. Each batch contains multiple copy activities that move data from source systems into landing areas and then into staging environments. The pipelines are pre-configured to execute these steps in the correct order.
Pipeline Batching and Activity Management
Because Azure Data Factory limits the number of activities per pipeline, BimlFlex calculates and organizes copy activities into batches. This batching ensures pipelines conform to platform limits without manual adjustments.
Each batch contains a manageable number of copy activities, which copy data from source tables into the landing area and then from landing tables into staging tables. This structured approach simplifies pipeline management and execution.
Summary
Building and deploying data pipelines manually can be tedious and prone to errors. Automating this process saves time and reduces complexity, empowering teams to focus on data insights rather than infrastructure setup.
By configuring your environment with the right settings, importing metadata from source systems, building pipeline assets automatically, and deploying them via scripts, you can establish reliable data movement workflows quickly. This approach works well with Azure Data Factory, leveraging its capabilities while overcoming common limitations like activity count restrictions.
In a matter of minutes, you can have a fully functional set of pipelines ready to run, moving data from your source into Azure SQL databases or Azure Synapse Analytics environments.
This method supports continuous integration and deployment, allowing for agile and repeatable data pipeline management.
If you're ready to stop hand-building pipelines, see first-hand how BimlFlex can automate every step, from metadata import to Azure deployment. Spend less time wiring connections and more time deliver insights with BimlFlex.
Schedule a demo today and start automating tomorrow.
Frequently Asked Questions (FAQ)
What is the main benefit of automating Azure Data Factory pipeline creation?
Automation reduces manual coding and deployment effort, minimizing errors and speeding up the delivery of data pipelines. It also helps enforce consistency and scalability across environments. This automation approach supports diverse use cases, from automating change data capture on Azure Data Factory for operational systems to building data marts for analytical workloads.
Do I need to manually configure all connections before building pipelines?
Yes, configuring connections and linked services is necessary initially. However, once set up, these configurations can be reused across multiple pipeline builds and deployments.
Can I use this process for different cloud environments or databases?
The approach focuses on Azure Data Factory and Azure SQL or Synapse databases but can be adapted for other supported cloud services or databases with proper metadata and connection configurations.
How does batching work in Azure Data Factory pipelines?
Because pipelines have a limit on the number of activities, batching splits copy operations into groups that fit within those limits. This allows large numbers of tables to be processed without hitting platform restrictions.
Is it possible to integrate this build and deployment process into CI/CD pipelines?
Yes, all build and deployment actions can be automated using command-line scripts and integrated into continuous integration and continuous deployment workflows for seamless pipeline lifecycle management.